Emerging Topics in Artificial Intelligence (ETAI) 2021
AUTHORS: Agnès Pérez-Millan, José Contador, Aida Niñerola-Baizán, Raúl Tudela, Xavier Setoain, Albert Lladó, Raquel Sanchez-Valle, Roser Sala-Llonch, for the Alzheimer’s Disease Neuroimaging Initiative.
TITLE: Statistical modelling of compromised longitudinal neuroimaging datasets: an application to alzheimer’s disease
CONFERENCE: Emerging Topics in Artificial Intelligence (ETAI) 2021
PLACE: Virtual Event
DATES: August 1 - 5, 2021
ABSTRACT:
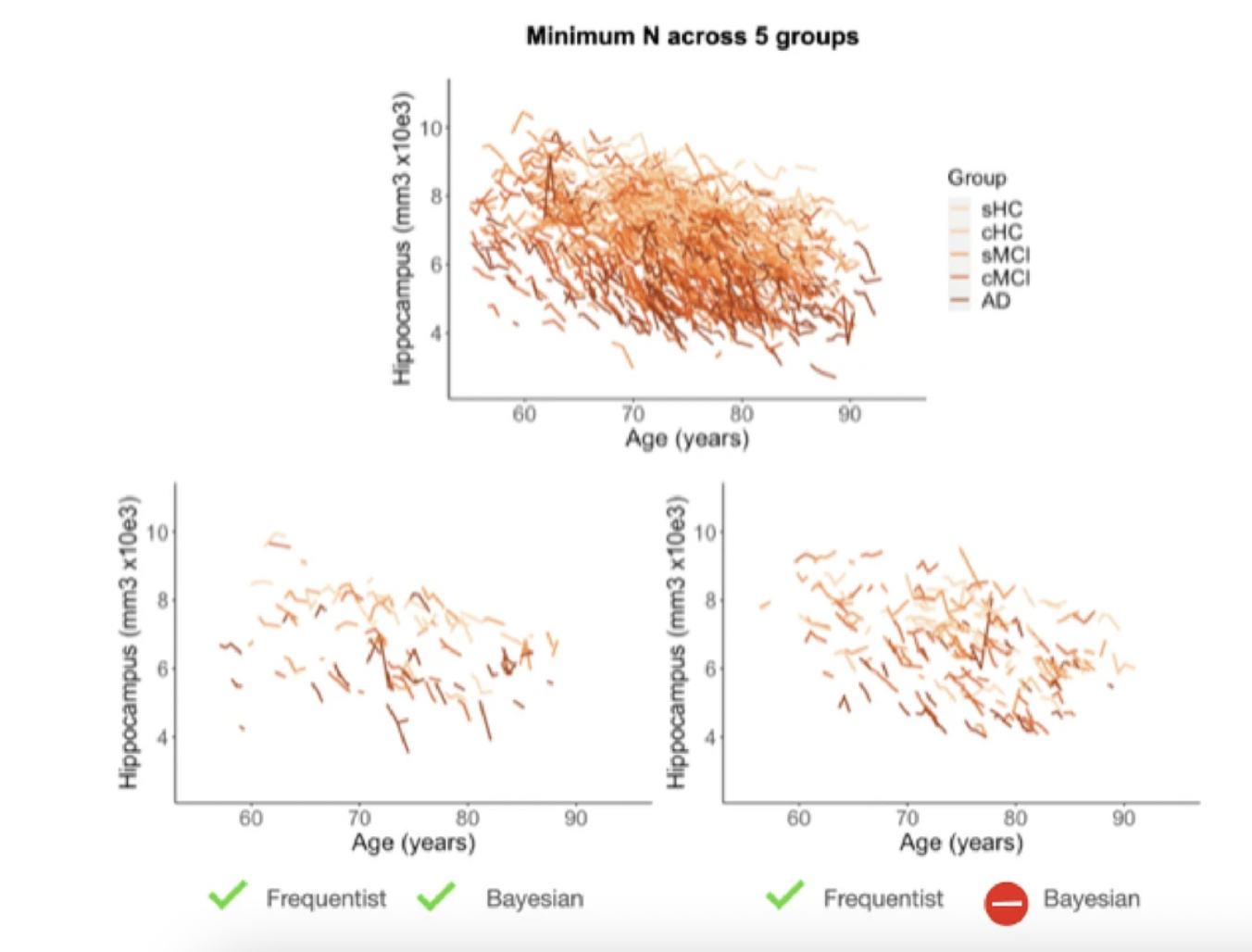
Large datasets of longitudinal data, made available for the neuroimage community, offer the possibility to study trajectories of biomarkers throughout the course of the diseases. For such modelling, approaches emerging from both the frequentist and the Bayesian frameworks have been suggested. When datasets are large, homogeneous, and balanced, both approaches seem to perform similarly. However, in compromised datasets, with limited number of samples and unbalanced data, this is not clear. Here we included data from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database to study the behaviour of different statistical approaches using different dataset configurations. We used the hippocampal volume (HV) at different timepoints and we analysed the capability of the methods to find differences across clinical groups. For that, we used a Linear Mixed Effects (LME) modelling under both the frequentist and the Bayesian approaches. We started with a large, homogeneous, and symmetric database, and we created different configurations, by sequentially removing data points, to simulate different real-life situations. Using the frequentist approach to predict conversion on mild cognitively impaired patients, we found that we need a mean of 115 subjects to differentiate converters vs non converters. When classifying between the five ADNI clinical groups we need 147 subjects (mean across datasets) to differentiate between all clinical groups. With the Bayesian approach, we demonstrated that the results were stronger and of higher interpretability, specially at the borderline significant datasets.